单选题 (共 5 题 ),每题只有一个选项正确
设 $X_1, X_2, X_3$ 是来自正态总体 $N\left(\mu, \sigma^2\right)$ 的简单随机样本, 则下列统计量中, ( ) 为 $\mu$ 的无偏估计且方差最小.
$\text{A.}$ $\frac{1}{2} X_1+\frac{1}{3} X_2+\frac{1}{6} X_3$
$\text{B.}$ $\frac{1}{3} X_1+\frac{1}{3} X_2+\frac{1}{3} X_3$
$\text{C.}$ $\frac{1}{5} X_1+\frac{2}{5} X_2+\frac{2}{5} X_3$
$\text{D.}$ $\frac{1}{7} X_1+\frac{2}{7} X_2+\frac{3}{7} X_3$
设 $X_1, X_2, \cdots, X_n$ 是来自总体 $X$ 的简单随机样本, $\bar{X}$ 为样本均值, $E(X)=\theta$. 检验 $H_0: \theta=0$; $H_1: \theta \neq 0$, 且拒绝域 $W_1=\{|\bar{X}|>1\}$ 和 $W_2=\{|\bar{X}|>2\}$ 分别对应显著性水平 $\alpha_1$ 和 $\alpha_2$, 则
$\text{A.}$ $\alpha_1=\alpha_2$.
$\text{B.}$ $\alpha_1>\alpha_2$.
$\text{C.}$ $\alpha_1 < \alpha_2$.
$\text{D.}$ $\alpha_1$ 和 $\alpha_2$ 的大小关系不确定.
设总体 $X \sim N\left(\mu, \sigma^2\right), X_1, X_2, \cdots, X_n$ 为来自总体 $X$ 的简单随机样本, $\bar{X}=\frac{1}{n} \sum_{i=1}^n X_i$, 已知 $k \sum_{i=1}^n\left(X_i-\bar{X}\right)^2$ 为 $\sigma^2$ 的无偏估计量, 则 $k=$.
$\text{A.}$ $\frac{1}{n}$
$\text{B.}$ $\frac{1}{2 n}$
$\text{C.}$ $\frac{1}{2(n-1)}$
$\text{D.}$ $\frac{1}{n-1}$
设总体 $X$ 的分布律为 $P\left\{X=(-1)^n n+p\right\}=\frac{1}{n(n+1)}, n=1,2, \cdots$, 其中 $p$ 为未知参数, $X_1, X_2, \cdots, X_n$ 为来自总体 $X$ 的简单随机样本, $\bar{X}$ 为样本均值, 则 $p$ 的矩估计量 $\hat{p}=$
$\text{A.}$ $\bar{X}-\ln 2$.
$\text{B.}$ $\bar{X}+\ln 2$.
$\text{C.}$ $\bar{X}-\ln 2+1$.
$\text{D.}$ $\bar{X}+\ln 2-1$.
一) 在假设检验中, 显著性水平 $\alpha$ 的意义是
$\text{A.}$ 原假设 $H_0$ 成立, 经检验被拒绝的概率
$\text{B.}$ 原假设 $H_0$ 成立, 经检验被接受的概率
$\text{C.}$ 原假设 $H_0$ 不成立, 经检验被拒绝的概率
$\text{D.}$ 原假设 $H_0$ 不成立, 经检验被接受的概率
填空题 (共 9 题 ),请把答案直接填写在答题纸上
设总体 $X$ 的密度函数为
$$
f(x)=\left\{\begin{array}{cc}
(a+1) x^a & 0 < x < 1 \\
0 & \text { 其它 }
\end{array}\right.
$$
其中 $a>-1$ 为末知参数, $\left(X_1, \cdots, X_n\right)$ 是从总体 $X$ 中抽取的一个样本, 求 $a$ 的矩估计量.
设 $X_1, X_2, \mathrm{~L}, X_n$ 为取自总体 $N\left(\mu, \sigma^2\right)$ 的一个样本, 其中 $\mu \in R, \sigma>0$ 均末知, $\bar{X}=\frac{1}{n} \sum_{i=1}^n X_i$,
$S^2=\frac{1}{n-1} \sum_{i=1}^n\left(X_i-\bar{X}\right)^2$ 分别表示样本均值和样本方差, 则对于给定的常数 $\alpha(0 < \alpha < 1)$, 区间 $\left[\bar{X}-\frac{S}{\sqrt{n}} t_{\alpha / 2}(n-1), \bar{X}+\frac{S}{\sqrt{n}} t_{\alpha / 2}(n-1)\right]$ 包含 $\mu$ 的概率是
设总体 $X$ 的分布函数为 $F(x)=\left\{\begin{array}{ll}1-\mathrm{e}^{-(x-\theta)^2}, & x \geqslant \theta, \\ 0, & x < \theta\end{array}(\theta>0\right.$ 为末知参数 $), X_1, X_2, \cdots$, $X_n$ 为来自总体 $X$ 的简单随机样本, $\bar{X}=\frac{1}{n} \sum_{i=1}^n X_i$, 则 $\theta$ 的矩估计量 $\hat{\theta}=$
设 $X_1, X_2$ 是来自正态总体 $N(\mu, 1)$ 的样本,下列三个估 计量是不是参数 $\mu$ 的无偏估计量,若是无偏估计量,试判断 哪一个较优?
$$
\begin{gathered}
\hat{\mu_1}=\frac{2}{3} X_1+\frac{1}{3} X_2, \hat{\mu}_1=\frac{1}{4} X_1+\frac{3}{4} X_2, \\
\hat{\mu}_1=\frac{1}{2} X_1+\frac{1}{2} X_2 .
\end{gathered}
$$
设 $\xi \sim f(x, \theta)=\left\{\begin{array}{cc}\frac{1}{\theta} e^{-\frac{x}{\theta}}, & x>0 \\ 0, & \text { 其它 }\end{array}(\theta>0)\right.$ , $x_1, x_2, \ldots, x_n$ 为 $\xi$ 的一组观察值,求 $\theta$ 的极大似然估计
设 $X_1, X_2, \cdots, X_n$ 是来自期望为 $\theta$ 的指数分布的简单随机样本, $Y_1, Y_2, \cdots, Y_m$ 是来自期望为 $2 \theta$ 的指数分布的简单随机样本, $X_1, X_2, \cdots, X_n, Y_1, Y_2, \cdots, Y_m$ 相互独立, 求 $\theta$ 的最大似然估计量 $\hat{\theta}$, 并求 $D(\hat{\theta})$.
在单边假设检验中, 原假设为 $H_0: \mu \leq \mu_0$, 则其备择假设为 $H_1$ :
设总体 $X$ 服从正态分布 $N\left(\mu, \sigma^2\right)$, 其中 $\sigma^2$ 未知, $x_1, x_2, \cdots, x_n$ 为其样本. 若假设检验问题为 $H_0: \mu=\mu_0, H_1: \mu \neq \mu_0$, 则采用的检验统计量表达现应为
某电子元件的使用寿命 $X$ (单位: 小时) 服从参数为 $\lambda$ 的指数分布, 其概率密度为 $f(x ; \lambda)=\left\{\begin{array}{ll}\lambda \mathrm{e}^{-\lambda x}, & x>0, \\ 0, & x \leq 0,\end{array}, \lambda>0\right.$. 现抽取 $n$ 个电子元件, 测得其平均使用寿命 $\bar{x}=1000$,求 $\lambda$ 的极大似然估计.
解答题 (共 25 题 ),解答过程应写出必要的文字说明、证明过程或演算步骤
设总体 $X$ 的密度函数为
$$
f(x)=\left\{\begin{array}{cc}
\frac{6 x}{\theta^3}(\theta-x) & 0 < x < \theta \\
0 & \text { 其它 }
\end{array},\right.
$$
其中 $\theta>0$ 是末知参数, $\left(X_1, \cdots, X_n\right)$ 是从该总体中抽取的一个样本.
(1). 求末知参数 $\theta$ 的矩估计 $\hat{\theta}$;
(2). 求 $D(\hat{\theta})$.
已知总体 $X$ 的分布律为
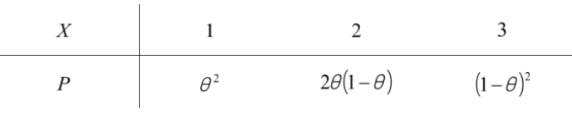
其中 $0 < \theta < 1$ 是末知参数, $\left(X_1, X_2, X_3\right)$ 是从中抽取的一个样本, 试求当样本观测值为 $\left(x_1=1, x_2=2, x_3=1\right)$ 时, 参数 $\theta$ 的最大似然估计值.
设总体 $X$ 的概率密度
$$
f(x ; \theta)= \begin{cases}1, & \theta-\frac{1}{2} \leqslant x \leqslant \theta+\frac{1}{2}, \\ 0, & \text { 其他, }\end{cases}
$$
其中 $-\infty < \theta < +\infty . X_1, X_2, \cdots, X_n$ 为取自总体 $X$ 的简单随机样本, 并记
$$
X_{(1)}=\min \left\{X_1, X_2, \cdots, X_n\right\}, X_{(n)}=\max \left\{X_1, X_2, \cdots, X_n\right\} .
$$
(1) 求参数 $\theta$ 的矩估计量 $\hat{\theta}_M$ 和最大似然估计量 $\hat{\theta}_L$;
(2) 判断 $\frac{X_{(1)}+X_{(n)}}{2}$ 是否为 $\theta$ 的无偏估计量, 并说明理由.
设总体 $X$ 的概率密度函数为 $f(x ; \theta)=\left\{\begin{array}{cc}a \theta x^{a-1} e^{-\theta x^a}, & x>0 \\ 0, & x \leq 0\end{array}\right.$, 若 $\theta>0$ 为末知参 数, $a$ 是已知常数, 若 $X_1, X_2, \cdots, X_n$ 是总体 $X$ 的简单随机样本, (I) 求参数 $\theta$ 的最大似然估计 $\hat{\theta}$, (II) 在 $a=1$ 时,考察 $\hat{\theta}^{-1}$ 是否为 $\theta^{-1}$ 的无偏估计 $E\left(\hat{\theta}^{-1}\right)$.
设 $X_1, X_2, \ldots, X_n$ 是来自总体 $X$ 的样本, $X$ 的密度函数为 $f(x ; \theta)=\left\{\begin{array}{c}\theta x^{0-1}, 0 < x < 1 \\ 0, \text { 其他 }\end{array}\right.$, 其中 $\theta>0$, 求
㟥数 $\theta$ 的最大似然估计
已知随机变量 $X_1, X_2, \ldots, X_{100}$ 独立同分布且均服从 $U(0,1)$, 令 $Y=X_1 \cdot X_2 \ldots X_{100}$, 求 $Y < e e^{-80}$ 的概 京的近似值.
设总体 $X$ 服从参数为 $p$ 的几何分布,其中 $0 < p < 1$ 为末知参数, $X_1, X_2, \mathrm{~K}, X_n$ 为取自该总体的 样本, $x_1, x_2, \mathrm{~L}, x_n$ 为相应的样本观测值.
1. 求参数 $p$ 的矩估计: 2 . 求 $p$ 的最大似然估计.
设总体$X$的概率密度为
$
f(x)=\left\{\begin{array}{cc}
(\theta+1) x^\theta, & 0 < x < 1 \\
0, & \text { 其他 }
\end{array}\right.
$
其中$\theta>-1$ 是末知参数, $X_1, X_2, \ldots, X_n$ 为来白总体的一个简单随机样本, $x_1, x_2, \ldots, x_n$ 为样本值, 求 $\theta$ 的矩 估计量和极大似然估计量.
设随机变墨 $X$ 在 $(1,4)$ 上服从均匀分布, 当 $X=x(1 < x < 4)$ 时, 随机变量 $Y$ 的条件密度 函数为 $f_{Y \mid X}(y \mid x)= \begin{cases}\frac{3 y^2}{x^3}, & 0 < y < x \text {, } \\ 0, & \text { 其他. }\end{cases}$
(1) 求 $Y$ 的密度函数;
(2) 求 $X, Y$ 的相关系数;
(3) 令 $Z=X-Y$, 求 $Z$ 的分布函数.
设总体 $X$ 的密度函数为
$$
f(x)= \begin{cases}\sqrt{\theta} x^{\sqrt{\theta}-1} & 0 < x < 1 \\ 0 & \text { 其它 }\end{cases}
$$
其中 $\theta>0$ 是末知参数, $\left(X_1, X_2, \cdots, X_n\right)$ 是从该总体中抽取 的一个样本. 求 $\theta$ 的最大似然估计量.
设总体 $X \sim N\left(\mu, \sigma^2\right),\left(X_1, X_2, \cdots\right.$, $\left.X_n\right)$ 是从总体 $X$ 中抽取的一个简单随机样本. $\bar{X}$ 与 $S^2$ 分别 表示样本均值与样本方差. 令 $T=\bar{X}^2-\frac{S^2}{n}$ ,求 $E(T)$ ,并 指出统计量 $T$ 是否为 $\mu^2$ 的无偏估计量.
设总体 $X$ 的概率密度函数为 $f(x)=\left\{\begin{array}{ll}\alpha \mathrm{e}^{-\alpha(x-\beta)}, & x \geqslant \beta, \\ 0, & \text { 其他, }\end{array}\right.$ 其中 $\alpha$ 为已知正常数, $\beta$ 为末知 正参数, $X_1, X_2, \cdots, X_n$ 是来自总体 $X$ 的简单随机样本.
(I) 求 $\beta$ 的最大似然估计量 $\hat{\beta}$;
(II) 判断 $\hat{\beta}$ 是否为无偏估计.
设总体 $X \sim F(x ; \theta)=\left\{\begin{array}{l}0, x < 1, \\ \theta, 1 \leqslant x < 2, \\ 2 \theta, 2 \leqslant x < 3, \\ 1, x>3\end{array} \quad\left(0 < \theta < \frac{1}{2}\right)\right.$, 一个来自总体 $X$ 的简单随机样本的经验
分布函数 $F_8(x)$ 的观察值为 $F_8(x)=\frac{1}{8}\left\{\begin{array}{l}0, x < 1 \\ 3,1 \leqslant x < 2 \\ 5,2 \leqslant x < 3 \\ 8, x \geqslant 3\end{array}\right.$, 求 $\theta$ 的矩估计值和极大似然估计值。
设总体 $X$ 的概率密度为 $f(x)=\left\{\begin{array}{ll}2(x-\theta) \mathrm{e}^{-(x-\theta)^2}, & x>\theta, \\ 0, & x \leqslant \theta,\end{array}\left(X_1, X_2, \cdots, X_n\right)\right.$ 为来自总体 $X$ 的简单随机样本.
(1) 求参数 $\theta$ 的矩估计量;
(2) 设 $U=\min \left\{X_1, X_2, \cdots, X_n\right\}$, 求 $E(U)$.
设总体 $X$ 的概率密度函数为 $f(x ; \theta)=\left\{\begin{array}{l}\frac{2 x}{\theta^2}, 0 < x < \theta, \\ 0, \quad \text { 其他, }\end{array}\left(X_1, X_2, \cdots, X_n\right)\right.$ 为来自总体 $X$的简单随机样本.
(I) 求参数 $\theta$ 的矩估计量 $\hat{\theta}_1$, 判断其无偏性;
(II) 求参数 $\theta$ 的最大似然估计量 $\hat{\theta}_2$;
(III) 求 (II) 中 $\hat{\theta}_2$ 的概率密度函数.
设总体 $X$ 的概率分布如下表, 其中 $0 < \theta < 1$ 为未知参数. 现从此总体中随机抽取 100 个样本, 发现有 17 个样本取值为 0,33 个样本取值为 1,50 个样本取值为 2 .
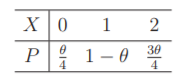
(1) 求 $\theta$ 的矩估计 $\hat{\theta}_1$ 和极大似然估计 $\hat{\theta}_2$; 并分别计算相应的估计值。
(2) $\hat{\theta}_1$ 和 $\hat{\theta}_2$ 是否是无偏的? 若否, 请修正。
(3) 请问修正后的估计那个更有效?
为比较甲和乙两处矿石的含灰率(\%), 分别从甲、乙两处随机抽取矿石6块, 甲处矿石含灰率数据是: $17,14,18,13,19$ 和 15 ; 而乙处矿石含灰率数据为: $16,19,20$, 22,18 和 19 . 假设两处矿石含灰率分别服从正态分布, 且总体独立, 均值和方差未知.试根据以上数据判断:
(1)(6 分) 在显著水平 0.05 下, 甲、乙两处矿石含灰率的方差是否相等?
(2)(9 分) 在显著水平 0.05 下, 乙处矿石含灰率的平均量是否显著地高于甲处矿石含灰率的平均量?
附录 分位数: $u_{0.025}=1.960, u_{0.05}=1.645, t_{0.025}(10)=2.228, t_{0.05}(10)=1.812, t_{0.025}(11)=$ $2.201, t_{0.05}(11)=1.796, t_{0.025}(12)=2.178, t_{0.05}(12)=1.782, \chi_{0.05}^2(1)=3.841, \chi_{0.05}^2(2)=$ $5.991, \chi_{0.05}^2(6)=12.591, F_{0.05}(5,5)=5.050, F_{0.025}(5,5)=7.146, F_{0.05}(6,6)=4.284$ $F_{0.025}(6,6)=5.820$.
设某种元件的使用寿命 $T$ 的分布函数为 $F(t)=\left\{\begin{array}{cc}1-\exp \left\{-\left(\frac{t}{\theta}\right)^m\right\}, & t \geq 0 ; \\ 0, & t < 0,\end{array}\right.$其中 $m>0$ 为已知参数, 而 $\theta>0$ 为未知参数. 随机取 $n$ 个这种元件, 测得它们的寿命分别为 $T_1, T_2, \cdots, T_n$. 记 $g(\theta)=\theta^m$.
(1) 试求 $g(\theta)$ 的极大似然估计 $\hat{g}\left(T_1, T_2, \cdots, T_n\right)$.
(2) 上述估计是否为无偏估计? 请证明你的结论.
中国科学技术大学 2019 级本科新生入学考试中, 某学院两个班级的英语科目各档成绩(从低到高)人数如下表所示:

我们能否认为这两个班级的英语水平大致相当? 显著性水平设为 $\alpha=0.05$.
附录:
$$
\begin{aligned}
& \Phi(1.645)=0.95, \Phi(1.96)=0.975 \\
& t_{15}(0.025)=2.131, t_{15}(0.05)=1.753, t_{16}(0.025)=2.12, t_{16}(0.05)=1.746 \\
& \chi_5^2(0.95)=1.145, \chi_5^2(0.05)=11.071, \chi_{15}^2(0.975)=6.262, \chi_{15}^2(0.025)=27.488 .
\end{aligned}
$$
设某手机每天销售量 $X$ (单位:万台) 的概率分布律为
$$
X \sim\left(\begin{array}{ccc}
10 & 15 & 20 \\
\theta^2 & \theta(1-\theta) & 1-\theta
\end{array}\right),
$$
其中 $0 < \theta < 1$ 为未知参数, 且每天的退货率为 $5 \%$, 现有一周的销售量: $15,10,10,15,20,20,15$.
(1) 求 $\theta$ 的最大似然估计值 $\hat{\theta}$;
(2) 记 $Y$ 为每天的退货量, 根据 (1) 中的 $\hat{\theta}$, 求 $E(Y)$.
$F(x)=\left\{\begin{array}{ll}1-\mathrm{e}^{-\frac{x^2}{\theta}}, & x \geqslant 0, \\ 0, & x < 0\end{array}\right.$ (其中 $\theta>0$ 为未知参数), $X_1, X_2, \cdots, X_n$ 为来自总体 $X$ 的简单随机样本.
(I) 求参数 $\theta$ 的矩估计量;
(II) 求参数 $\theta$ 的最大似然估计量.
设 $X_1, X_2, \cdots, X_n$ 是来自区间 $[\theta, \theta+1]$ 上均匀分布的总体 $X$ 的简单随机样本, 试求
(I) 参数 $\theta$ 的矩估计量 $\hat{\theta}_1$;
(II) 参数 $\theta$ 的最大似然估计量 $\hat{\theta}_2$;
(III) $E\left(\hat{\theta}_1\right)$ 和 $D\left(\hat{\theta}_1\right)$ 的值.
设 $X_1, \cdots, X_{16}$ 是正态总体 $N(\mu, 4)$ 的一个样本, 其观测值为 $x_1, \cdots, x_{16}$, 考虑下列检验问题:
$H_0: \mu=6, \quad H_1: \mu \neq 6 .$
检验的拒绝域为 $W=\{|\bar{x}-6| \geqslant c\}$ (其中 $\bar{x}=\frac{1}{16} \sum_{i=1}^{16} x_i$ ).
(I) 求出显著性水平为 $\alpha=0.05$ 时的常数 $c$ 的值 (精确到 2 位小数);
(II) 求该检验在 $\mu=6.5$ 处犯第二类错误的概率 (精确到 2 位小数).
$$
(\Phi(0.96)=0.832, \Phi(1.96)=0.975, \Phi(2.96)=0.999 .)
$$
设总体 $X$ 服从 $(0, \theta]$ 上的均匀分布, $\theta>0, X_1, X_2, \cdots, X_n$ 为来自总体 $X$ 的简单随机样本.
(1) 求 $\theta$ 的最大似然估计量 $\hat{\theta}$;
(2) 求 $Z=\frac{\hat{\theta}}{\theta}$ 的分布函数;
(3) 若 $P\left\{\hat{\theta} < \theta < \theta_0\right\}=1-\alpha, 0 < \alpha < 1$, 求 $\theta_0$.
设随机变量 $X$ 与 $Y$ 相互独立, 且分别服从正态分布 $\mathrm{N}\left(\mu, \sigma^2\right)$ 与 $\mathrm{N}\left(2 \mu, \sigma^2\right)$, 其中 $\sigma>0$ 为末知参数, 记 $Z=2 X-Y$.
(I) 求 $Z$ 的概率密度 $f(z)$;
(II) 设 $Z_1, Z_2, \cdots, Z_n$ 为来自总体 $Z$ 的简单随机样本, 求 $\sigma^2$ 的极大似然估计量 $\hat{\sigma}^2$;
(III) 求 $\mathrm{E}\left(\hat{\sigma}^2\right)$ 和 $\mathrm{D}\left(\hat{\sigma}^2\right)$.